
Mika is for hearing
The phonological design of the new language is easy to speak and easy to hear.


Designing Mika: Mika is Hard to Mishear
I’ve been quietly building a new conlang called Mika, and here I share the thinking behind its sound system, how we speak it. My goal is clarity. I want a language where the most important little words (the grammar glue) stay clear even when people whisper, talk fast, or speak with their mouth half-full. That means starting from the most common, sturdy sounds across human languages and being deliberate about how far apart they need to feel.

Starting with the Strongest Foundations
I began by looking at phonemes that show up reliably in languages as different as English, Mandarin, Arabic, Swahili, and Japanese. The ultra-core set that survived every filter was simple: /a i u m n t k/. These feel universal for a reason — they’re easy to produce and relatively easy to tell apart even in noisy or degraded conditions. From there I expanded to a full inventory that still feels grounded:
- Vowels: e i a u o
- Consonants: b t k g d s m n y l
- One-to-one matching graphemes, many looking like the IPA sound symbols
- Fifty basic consonant-vowel syllables plus five more vowel-only syllables
- Up to 55 more special one-syllable words
Nothing fancy, but enough room to breathe.
Why Distance Matters (and How I Measured It)
Early on I realized I didn’t just want “different” sounds — I wanted safely different sounds for the high-frequency grammar words that hold sentences together.I used a weighted Hamming distance based on phonological features, informed by classic perception studies like Miller & Nicely (1955). In plain terms: some differences (like nasal vs. stop, or voicing) are perceptually “expensive” to confuse, so I gave them higher costs in the math. Place differences get lower weight because they’re more fragile in noise.
Core Phoneme Set
My first attempts to create a distance chart using the core phonemes came up with this:
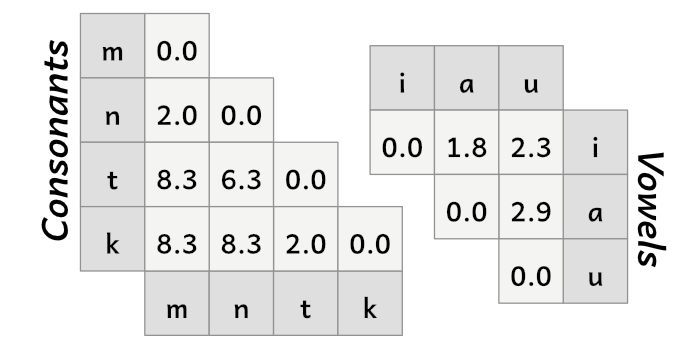
The numbers aren’t sacred, but they helped me make consistent choices instead of guessing.
All Phoneme Distances
Moving to the full phoneme set and tweaking weighting and changing the distance method (Hamming) creates a similar pattern. The full distance arrays are too messy for here; weighted hamming tables and graphics will be shared later.
I'll leave this with an image of weighted hammocks.

The Safest Twelve Syllables
I pulled the twelve strongest consonant-vowel (CV) syllables from the original ultra-core set and ranked them for clarity. These are the ones I want to use for the important grammatical markers.
All of these sit at comfortable distances from one another (minimum 4.0 in the weighted system). They feel distinct even when I whisper them or say them quickly. With context distinction, all can be used.
The most distinctive got narrowed down, resulting in prohibited pairs of the consonant leaving these options:
ma/na ta/ka mu/nu tu/ku mi/ni ti/ki
From that I might select these for the key function words:
ma ka nu tu ni ki
Practical Rules I’m Following
For single-syllable function words: minimum distance of 4.0 using one of the distance measures. No exceptions! (I think; I'm still tweaking distance measurements.) For ordinary lexical words in the same semantic domain: at least 3.5–4.0. It’s fine to have kana “indivisible” and kama “snake” — different domains, different mental neighborhoods. But I won’t let the two quote-introducing particles sit too close.
I also keep reminding myself that real speech is messy. Whispering normally wipes out voicing, but the d and g are further back than t and k. Talking with your mouth full blurs place cues. The core set holds up surprisingly well under those conditions because it leans on nasals, voiceless stops, and nicely dispersed vowels.

What Feels Solid So Far
I like that the system is humble in its ingredients but deliberate in its choices. It respects real human perception instead of just chasing aesthetic symmetry. The one-to-one orthography makes it approachable. And having a clear grammar-core foundation gives the whole language a reliable skeleton before I start growing the flesh of vocabulary and grammar.
There’s still plenty to do, but the foundation feels right.
I’d love to hear your thoughts if you’ve wrestled with similar decisions in your own conlangs. What sounds have you found most reliable (or most treacherous) in practice?
I'd love to hear from those of you struggling to learn languages. What are some problem areas in pronunciation and hearing?